Maksim E. Eren
Scientist
Los Alamos National Laboratory
Biography
Maksim E. Eren is a scientist in the Computational Intelligence & Modeling (A-1) group at Los Alamos National Laboratory (LANL) and a LANL Center for National Security and International Studies (CNSIS) Fellow. He is an alumnus of the Scholarship for Service CyberCorps program. Maksim graduated Summa Cum Laude with a Bachelor’s degree in Computer Science from the University of Maryland Baltimore County (UMBC) in 2020 and earned his Master’s degree from the same institution in 2022. In 2024, he received his Ph.D. from UMBC, focusing on tensor decomposition methods for malware characterization.
Maksim’s research interests span an interdisciplinary set of topics in artificial intelligence (AI) and applied data science. He is particularly interested in leveraging AI to address challenges across diverse domains, including biology and cybersecurity. Maksim’s work in AI and data science include tensor decomposition, pattern extraction, natural language processing (NLP), malware characterization, anomaly detection, text mining, large language models (LLMs), knowledge graphs (KGs), high-performance computing (HPC), and data privacy. In addition to research, Maksim actively develops high-performance software and efficient machine learning (ML) pipelines optimized for extra-large datasets and real-world applications. At LANL, Maksim was a member of the 2021 R&D 100 winning project SmartTensors AI, where he has released a fast tensor decomposition and anomaly detection software, contributed to the design and development of various other tensor decomposition libraries, and developed state-of-the-art text mining tools.
Interests
- Artificial Intelligence
- Data Science
- Tensor Decomposition
- Cybersecurity
- Natural Language Processing
- High Performance Computing
- Knowledge Representation
- Pattern Extraction
Education
PhD in Computer Science, 2024
University of Maryland, Baltimore County (UMBC)
MS in Computer Science, 2022
University of Maryland, Baltimore County (UMBC)
BS in Computer Science, 2020
University of Maryland, Baltimore County (UMBC)
AA in Computer Science, 2018
Montgomery College (MC)
Featured Publications
Giving AI a headache: acoustic adversarial attacks to computer vision applications
Artificial Intelligence (AI) is increasingly used to automate a variety of real-world computer vision (CV) applications, such as autonomous vehicle control, facial recognition, and security cameras. Recent research has shown that acoustic vibration can induce real physical motion in cameras, interfering with their internal stabilization mechanisms. Because the motion falls outside the conditions the stabilization system was designed to handle, the system introduces artifacts into the frame, causing AI-based CV models to misclassify, miss targets, or hallucinate objects. Previous work used ultrasonic frequencies (>20 kHz) to perform short-range attacks, which limits them to short distances due to the attenuation exhibited by high frequencies. In this work, we investigate acoustic attacks using lower frequencies in the audible range (<20 kHz), and we further expand our analysis to include how various image and object features are affected by the attacks. Specifically, we performed physical experiments to demonstrate the viability of our attacks on an off-theshelf object detection model (YOLO11) by resonating a commercially available camera with various frequencies. Based on our results, we provide insights into several factors that make an AI CV system more vulnerable to these attacks, which could help inform the development of future mitigation strategies.
Prompt Programming for Cultural Bias and Alignment of Large Language Models
Culture shapes reasoning, values, prioritization, and strategic decision-making, yet large language models (LLMs) often exhibit cultural biases that misalign with target populations. As LLMs are increasingly used for strategic decision-making, policy support, and document engineering tasks such as summarization, categorization, and compliance-oriented auditing, improving cultural alignment is important for ensuring that downstream analyses and recommendations reflect target-population value profiles rather than default model priors. Previous work introduced a survey-grounded cultural alignment framework and showed that culture-specific prompting can reduce misalignment, but it primarily evaluated proprietary models and relied on manual prompt engineering. In this paper, we validate and extend that framework by reproducing its social sciences survey based projection and distance metrics on open-weight LLMs, testing whether the same cultural skew and benefits of culture conditioning persist outside closed LLM systems. Building on this foundation, we introduce use of prompt programming with DSPy for this problem-treating prompts as modular, optimizable programs-to systematically tune cultural conditioning by optimizing against cultural-distance objectives. In our experiments, we show that prompt optimization often improves upon cultural prompt engineering, suggesting prompt compilation with DSPy can provide a more stable and transferable route to culturally aligned LLM responses.
Rethinking Science in the Age of Artificial Intelligence
Artificial intelligence (AI) is reshaping how research is conceived, conducted, and communicated across fields from chemistry to biomedicine. This commentary examines how AI is transforming the research workflow. AI systems now help researchers manage the information deluge, filtering the literature, surfacing cross-disciplinary links for ideas and collaborations, generating hypotheses, and designing and executing experiments. These developments mark a shift from AI as a mere computational tool to AI as an active collaborator in science. Yet this transformation demands thoughtful integration and governance. We argue that at this time AI must augment but not replace human judgment in academic workflows such as peer review, ethical evaluation, and validation of results. This paper calls for the deliberate adoption of AI within the scientific practice through policies that promote transparency, reproducibility, and accountability.
News
AI tensor network-based computational framework cracks a 100-year-old physics challenge

Using AI to develop enhanced cybersecurity measures

Not too big - Machine learning tames huge datasets

Our paper that sets a new world record

R&D 100 winner of the day - SmartTensors AI Platform

Recent Publications
Recent Posts
Tensor Decomposition for Cybersecurity
Selected list of publications on tensor decomposition methods for cybersecurity and data privacy.
Anaconda and Jupyter Setup for Research
Using Anaconda and Jupyter for research has become a daily routine for me. Here I list some of the most frequent commands I utilize when setting up conda environments with Jupyter for my research proejcts.
Python Documentation with Sphinx
Documenting your code is an important part of any project from developing a library to research code. In this blog post, I will give a brief tutorial on how to utilize Sphinx for documenting Python code. Sphinx is a tool utilized by several popular libraries. It turns the in-code comments into a user-friendly and modern documentation website.
screen + Jupyter - A way to execute long running Jupyter notebooks headless mode
Jupyter notebooks is a great way to work on research code. But notebooks used to analyse large datasets take long time to execute. And if our local or remote terminal session dies, our notebook dies too, resulting in waste of time. Here I summarize how we can run a notebook in headless mode in a screen session which allows us to run Jupyter notebook indipendent from the terminal session.
Software
lanl/THOR
The THOR Project (Tensors for High-dimensional Object Representation) aims to advance the state-of-the-art in tensor calculations, manipulation, and research. We strive to provide a high-performance tensor library for various scientific applications, containing ready-to-use utilities and applicaions in Fortran, Matlab, and Python.
lanl/T-ELF
Tensor Extraction of Latent Features (T-ELF) is one of the machine learning software packages developed as part of the R&D 100 winning SmartTensors AI project at Los Alamos National Laboratory (LANL). T-ELF presents an array of customizable software solutions crafted for analysis of datasets.

pyCP_ALS
pyCP_ALS is the Python implementation of CP-ALS algorithm that was originally introduced in the MATLAB Tensor Toolbox.
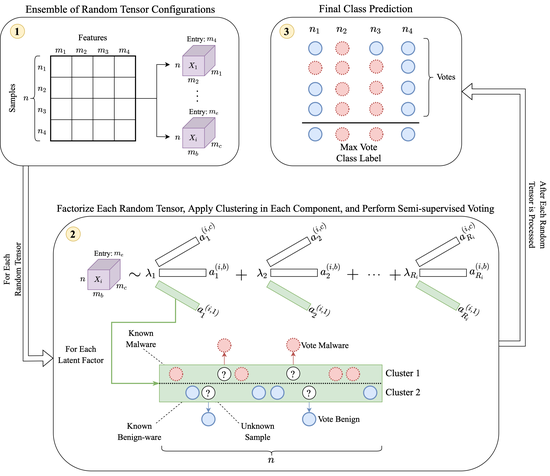
RFoT
Random Forest of Tensors (RFoT) is a novel ensemble semi-supervised classification algorithm based on tensor decomposition. We show the capabilities of RFoT when classifying Windows Portable Executable (PE) malware and benign-ware.
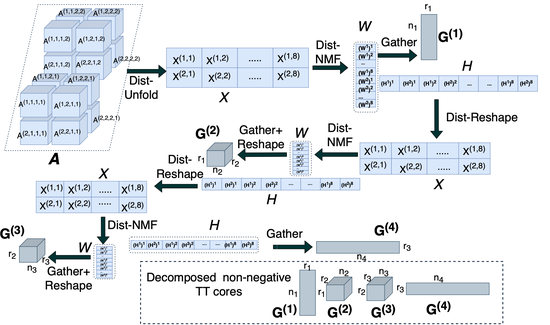
lanl/pyDNTNK
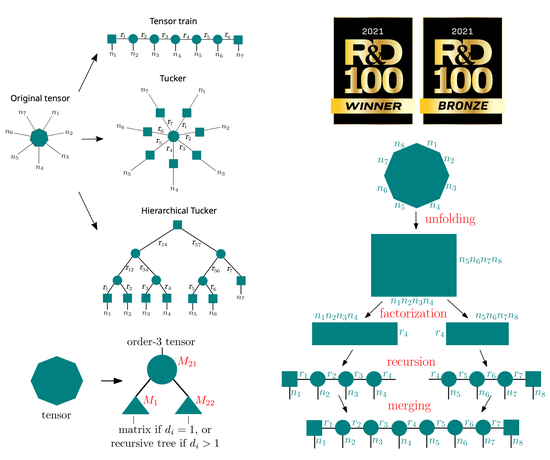
pyDNTNK is a software package for applying non-negative Hierarchical Tensor decompositions such as Tensor train and Hierarchical Tucker decompositons in a distributed fashion to large datasets. It is built on top of pyDNMFk.
lanl/pyQBTNs
pyQBTNs is a Python library for boolean matrix and tensor factorization using D-Wave quantum annealers.
lanl/pyCP_APR
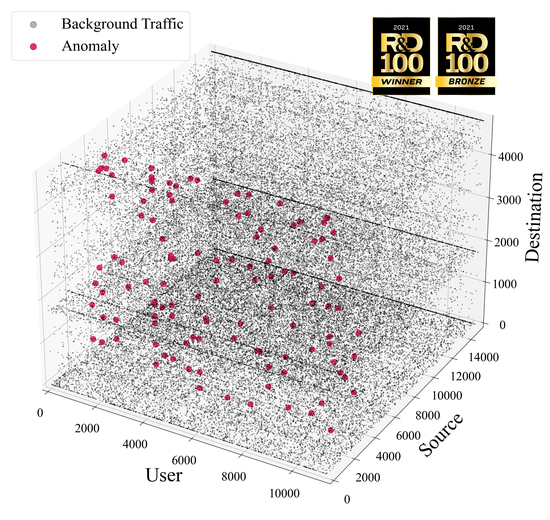
pyCP_APR is a Python library for tensor decomposition and anomaly detection that is developed as part of the R&D 100 award wining SmartTensors project. It is designed for the fast analysis of large datasets by accelerating computation speed using GPUs.

lanl/pyDNMFk
pyDNMFk is a software package for applying non-negative matrix factorization in a distributed fashion to large datasets. It has the ability to minimize the difference between reconstructed data and the original data through various norms (Frobenious, KL-divergence).
lanl/pyDRESCALk
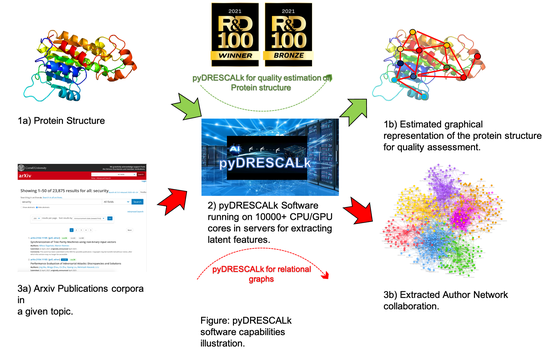
pyDRESCALk is a software package for applying non-negative RESCAL decomposition in a distributed fashion to large datasets. It can be utilized for decomposing relational datasets.
Recent Talks
Tensor Decomposition Methods for Cybersecurity

Anomalous Event Detection using Non-Negative Poisson Tensor Factorization
