Maksim E. Eren
Scientist
Los Alamos National Laboratory
Biography
Maksim E. Eren is an early career scientist in the Information Systems and Modeling (A-1) group at Los Alamos National Laboratory (LANL) and a LANL Center for National Security and International Studies (CNSIS) Fellow. He is an alumnus of the Scholarship for Service CyberCorps program. Maksim graduated Summa Cum Laude with a Bachelor’s degree in Computer Science from the University of Maryland Baltimore County (UMBC) in 2020 and earned his Master’s degree from the same institution in 2022. In 2024, he received his Ph.D. from UMBC, focusing on tensor decomposition methods for malware characterization.
Maksim’s research interests span an interdisciplinary set of topics in artificial intelligence (AI) and applied data science. He is particularly interested in leveraging AI to address challenges across diverse domains, including biology and cybersecurity. Maksim’s work in AI and data science include tensor decomposition, pattern extraction, natural language processing (NLP), malware characterization, anomaly detection, text mining, large language models (LLMs), knowledge graphs (KGs), high-performance computing (HPC), and data privacy. In addition to research, Maksim actively develops high-performance software and efficient machine learning (ML) pipelines optimized for extra-large datasets and real-world applications. At LANL, Maksim was a member of the 2021 R&D 100 winning project SmartTensors AI, where he has released a fast tensor decomposition and anomaly detection software, contributed to the design and development of various other tensor decomposition libraries, and developed state-of-the-art text mining tools.
Interests
- Artificial Intelligence
- Data Science
- Tensor Decomposition
- Cybersecurity
- Natural Language Processing
- High Performance Computing
- Knowledge Representation
- Pattern Extraction
Education
PhD in Computer Science, 2024
University of Maryland, Baltimore County (UMBC)
MS in Computer Science, 2022
University of Maryland, Baltimore County (UMBC)
BS in Computer Science, 2020
University of Maryland, Baltimore County (UMBC)
AA in Computer Science, 2018
Montgomery College (MC)
Featured Publications
Rethinking Science in the Age of Artificial Intelligence
Artificial intelligence (AI) is reshaping how research is conceived, conducted, and communicated across fields from chemistry to biomedicine. This commentary examines how AI is transforming the research workflow. AI systems now help researchers manage the information deluge, filtering the literature, surfacing cross-disciplinary links for ideas and collaborations, generating hypotheses, and designing and executing experiments. These developments mark a shift from AI as a mere computational tool to AI as an active collaborator in science. Yet this transformation demands thoughtful integration and governance. We argue that at this time AI must augment but not replace human judgment in academic workflows such as peer review, ethical evaluation, and validation of results. This paper calls for the deliberate adoption of AI within the scientific practice through policies that promote transparency, reproducibility, and accountability.
Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing (NLP) tasks, such as question-answering, sentiment analysis, text summarization, and machine translation. However, the ever-growing complexity of LLMs demands immense computational resources, hindering the broader research and application of these models. To address this, various parameter-efficient fine-tuning strategies, such as Low-Rank Approximation (LoRA) and Adapters, have been developed. Despite their potential, these methods often face limitations in compressibility. Specifically, LoRA struggles to scale effectively with the increasing number of trainable parameters in modern large scale LLMs. Additionally, Low-Rank Economic Tensor-Train Adaptation (LoRETTA), which utilizes tensor train decomposition, has not yet achieved the level of compression necessary for fine-tuning very large scale models with limited resources. This paper introduces Tensor Train Low-Rank Approximation (TT-LoRA), a novel parameter-efficient fine-tuning (PEFT) approach that extends LoRETTA with optimized tensor train (TT) decomposition integration. By eliminating Adapters and traditional LoRA-based structures, TT-LoRA achieves greater model compression without compromising downstream task performance, along with reduced inference latency and computational overhead. We conduct an exhaustive parameter search to establish benchmarks that highlight the trade-off between model compression and performance. Our results demonstrate significant compression of LLMs while maintaining comparable performance to larger models, facilitating their deployment on resource-constraint platforms.
Semi-supervised Classification of Malware Families Under Extreme Class Imbalance via Hierarchical Non-Negative Matrix Factorization with Automatic Model Selection
Identification of the family to which a malware specimen belongs is essential in understanding the behavior of the malware and developing mitigation strategies. Solutions proposed by prior work, however, are often not practicable due to the lack of realistic evaluation factors. These factors include learning under class imbalance, the ability to identify new malware, and the cost of production-quality labeled data. In practice, deployed models face prominent, rare, and new malware families. At the same time, obtaining a large quantity of up-to-date labeled malware for training a model can be expensive. In this paper, we address these problems and propose a novel hierarchical semi-supervised algorithm, which we call the HNMFk Classifier, that can be used in the early stages of the malware family labeling process. Our method is based on non-negative matrix factorization with automatic model selection, that is, with an estimation of the number of clusters. With HNMFk Classifier, we exploit the hierarchical structure of the malware data together with a semi-supervised setup, which enables us to classify malware families under conditions of extreme class imbalance. Our solution can perform abstaining predictions, or rejection option, which yields promising results in the identification of novel malware families and helps with maintaining the performance of the model when a low quantity of labeled data is used. We perform bulk classification of nearly 2,900 both rare and prominent malware families, through static analysis, using nearly 388,000 samples from the EMBER-2018 corpus. In our experiments, we surpass both supervised and semi-supervised baseline models with an F1 score of 0.80.
News
AI tensor network-based computational framework cracks a 100-year-old physics challenge

Using AI to develop enhanced cybersecurity measures

Not too big - Machine learning tames huge datasets

Our paper that sets a new world record

R&D 100 winner of the day - SmartTensors AI Platform

Recent Publications
Recent Posts
Tensor Decomposition for Cybersecurity
Selected list of publications on tensor decomposition methods for cybersecurity and data privacy.
Anaconda and Jupyter Setup for Research
Using Anaconda and Jupyter for research has become a daily routine for me. Here I list some of the most frequent commands I utilize when setting up conda environments with Jupyter for my research proejcts.
Python Documentation with Sphinx
Documenting your code is an important part of any project from developing a library to research code. In this blog post, I will give a brief tutorial on how to utilize Sphinx for documenting Python code. Sphinx is a tool utilized by several popular libraries. It turns the in-code comments into a user-friendly and modern documentation website.
screen + Jupyter - A way to execute long running Jupyter notebooks headless mode
Jupyter notebooks is a great way to work on research code. But notebooks used to analyse large datasets take long time to execute. And if our local or remote terminal session dies, our notebook dies too, resulting in waste of time. Here I summarize how we can run a notebook in headless mode in a screen session which allows us to run Jupyter notebook indipendent from the terminal session.
Software
lanl/THOR
The THOR Project (Tensors for High-dimensional Object Representation) aims to advance the state-of-the-art in tensor calculations, manipulation, and research. We strive to provide a high-performance tensor library for various scientific applications, containing ready-to-use utilities and applicaions in Fortran, Matlab, and Python.
lanl/T-ELF
Tensor Extraction of Latent Features (T-ELF) is one of the machine learning software packages developed as part of the R&D 100 winning SmartTensors AI project at Los Alamos National Laboratory (LANL). T-ELF presents an array of customizable software solutions crafted for analysis of datasets.

pyCP_ALS
pyCP_ALS is the Python implementation of CP-ALS algorithm that was originally introduced in the MATLAB Tensor Toolbox.
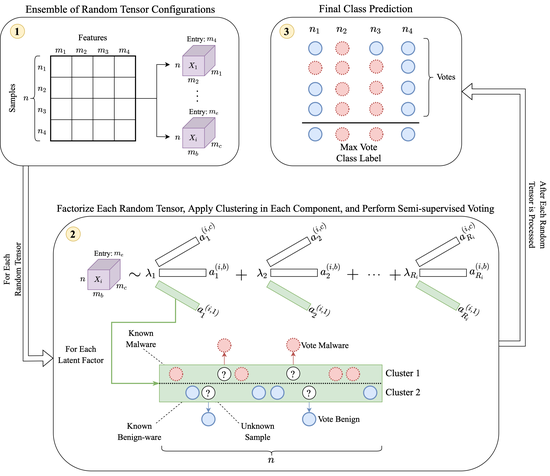
RFoT
Random Forest of Tensors (RFoT) is a novel ensemble semi-supervised classification algorithm based on tensor decomposition. We show the capabilities of RFoT when classifying Windows Portable Executable (PE) malware and benign-ware.
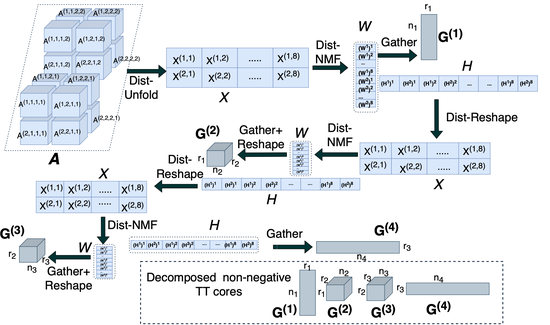
lanl/pyDNTNK
pyDNTNK is a software package for applying non-negative Hierarchical Tensor decompositions such as Tensor train and Hierarchical Tucker decompositons in a distributed fashion to large datasets. It is built on top of pyDNMFk.
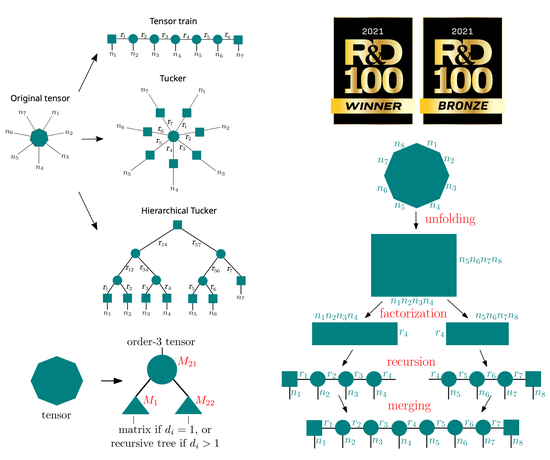
lanl/pyQBTNs
pyQBTNs is a Python library for boolean matrix and tensor factorization using D-Wave quantum annealers.
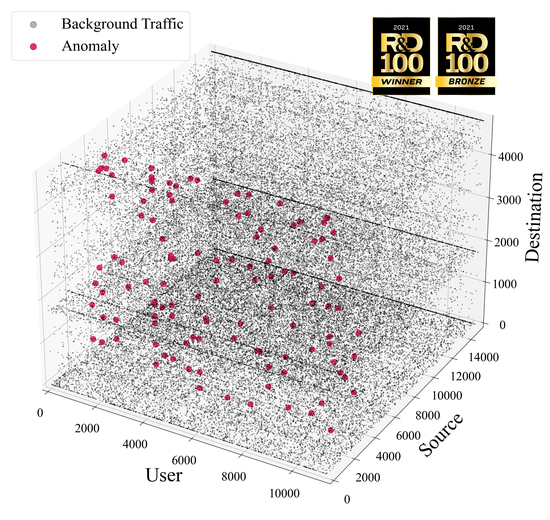
lanl/pyCP_APR
pyCP_APR is a Python library for tensor decomposition and anomaly detection that is developed as part of the R&D 100 award wining SmartTensors project. It is designed for the fast analysis of large datasets by accelerating computation speed using GPUs.

lanl/pyDNMFk
pyDNMFk is a software package for applying non-negative matrix factorization in a distributed fashion to large datasets. It has the ability to minimize the difference between reconstructed data and the original data through various norms (Frobenious, KL-divergence).
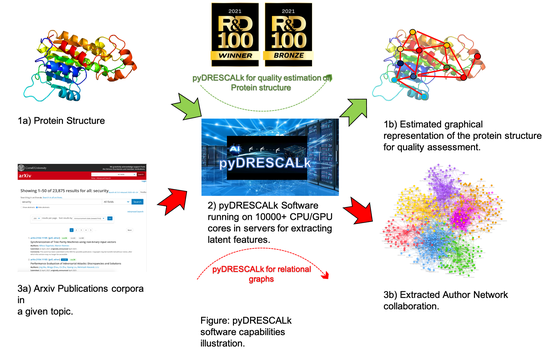
lanl/pyDRESCALk
pyDRESCALk is a software package for applying non-negative RESCAL decomposition in a distributed fashion to large datasets. It can be utilized for decomposing relational datasets.
Recent Talks
Tensor Decomposition Methods for Cybersecurity

Anomalous Event Detection using Non-Negative Poisson Tensor Factorization
